Data Transforms (Need to update)¶
Design of Data transforms pipeline¶
Following typical conventions, we use Dataset and DataLoader for data loading
with multiple workers. Dataset returns a dict of data items corresponding
the arguments of models’ forward method.
The data transforms pipeline and the dataset is decomposed. Usually a dataset defines how to process the annotations and a data transforms pipeline defines all the steps to prepare a data dict. A pipeline consists of a sequence of data transforms. Each operation takes a dict as input and also output a dict for the next transform.
We present a classical pipeline in the following figure. The blue blocks are pipeline operations. With the pipeline going on, each operator can add new keys (marked as green) to the result dict or update the existing keys (marked as orange).
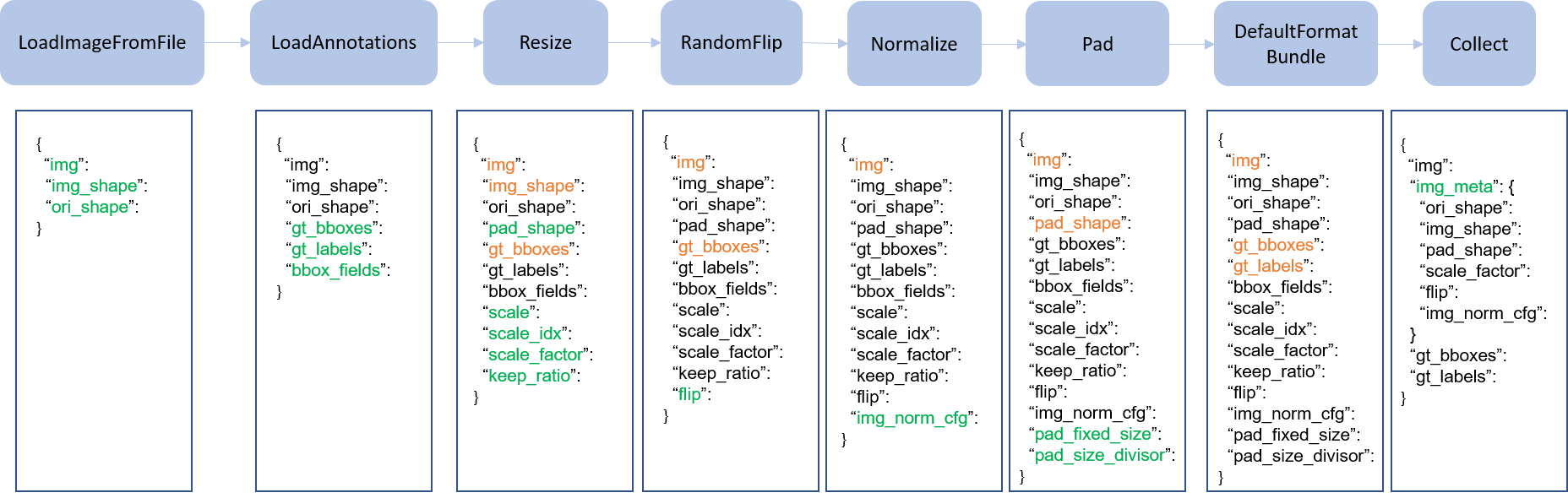
Here is a pipeline example for Faster R-CNN.
train_pipeline = [ # Training data processing pipeline
dict(type='LoadImageFromFile', backend_args=backend_args), # First pipeline to load images from file path
dict(
type='LoadAnnotations', # Second pipeline to load annotations for current image
with_bbox=True), # Whether to use bounding box, True for detection
dict(
type='Resize', # Pipeline that resize the images and their annotations
scale=(1333, 800), # The largest scale of image
keep_ratio=True # Whether to keep the ratio between height and width
),
dict(
type='RandomFlip', # Augmentation pipeline that flip the images and their annotations
prob=0.5), # The probability to flip
dict(type='PackDetInputs') # Pipeline that formats the annotation data and decides which keys in the data should be packed into data_samples
]
test_pipeline = [ # Testing data processing pipeline
dict(type='LoadImageFromFile', backend_args=backend_args), # First pipeline to load images from file path
dict(type='Resize', scale=(1333, 800), keep_ratio=True), # Pipeline that resize the images
dict(
type='PackDetInputs', # Pipeline that formats the annotation data and decides which keys in the data should be packed into data_samples
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
'scale_factor'))
]