Semi-supervised Object Detection¶
Semi-supervised object detection uses both labeled data and unlabeled data for training. It not only reduces the annotation burden for training high-performance object detectors but also further improves the object detector by using a large number of unlabeled data.
A typical procedure to train a semi-supervised object detector is as below:
Prepare and split dataset
Configure multi-branch pipeline
Configure semi-supervised dataloader
Configure semi-supervised model
Configure MeanTeacherHook
Configure TeacherStudentValLoop
Prepare and split dataset¶
We provide a dataset download script, which downloads the coco2017 dataset by default and decompresses it automatically.
python tools/misc/download_dataset.py
The decompressed dataset directory structure is as below:
mmdetection
├── data
│ ├── coco
│ │ ├── annotations
│ │ │ ├── image_info_unlabeled2017.json
│ │ │ ├── instances_train2017.json
│ │ │ ├── instances_val2017.json
│ │ ├── test2017
│ │ ├── train2017
│ │ ├── unlabeled2017
│ │ ├── val2017
There are two common experimental settings for semi-supervised object detection on the coco2017 dataset:
(1) Split train2017 according to a fixed percentage (1%, 2%, 5% and 10%) as a labeled dataset, and the rest of train2017 as an unlabeled dataset. Because the different splits of train2017 as labeled datasets will cause significant fluctuation on the accuracy of the semi-supervised detectors, five-fold cross-validation is used in practice to evaluate the algorithm. We provide the dataset split script:
python tools/misc/split_coco.py
By default, the script will split train2017 according to the labeled data ratio 1%, 2%, 5% and 10%, and each split will be randomly repeated 5 times for cross-validation. The generated semi-supervised annotation file name format is as below:
the name format of labeled dataset:
instances_train2017.{fold}@{percent}.jsonthe name format of unlabeled dataset:
instances_train2017.{fold}@{percent}-unlabeled.json
Here, fold is used for cross-validation, and percent represents the ratio of labeled data. The directory structure of the divided dataset is as below:
mmdetection
├── data
│ ├── coco
│ │ ├── annotations
│ │ │ ├── image_info_unlabeled2017.json
│ │ │ ├── instances_train2017.json
│ │ │ ├── instances_val2017.json
│ │ ├── semi_anns
│ │ │ ├── instances_train2017.1@1.json
│ │ │ ├── instances_train2017.1@1-unlabeled.json
│ │ │ ├── instances_train2017.1@2.json
│ │ │ ├── instances_train2017.1@2-unlabeled.json
│ │ │ ├── instances_train2017.1@5.json
│ │ │ ├── instances_train2017.1@5-unlabeled.json
│ │ │ ├── instances_train2017.1@10.json
│ │ │ ├── instances_train2017.1@10-unlabeled.json
│ │ │ ├── instances_train2017.2@1.json
│ │ │ ├── instances_train2017.2@1-unlabeled.json
│ │ ├── test2017
│ │ ├── train2017
│ │ ├── unlabeled2017
│ │ ├── val2017
(2) Use train2017 as the labeled dataset and unlabeled2017 as the unlabeled dataset. Since image_info_unlabeled2017.json does not contain categories information, the CocoDataset cannot be initialized, so you need to write the categories of instances_train2017.json into image_info_unlabeled2017.json and save it as instances_unlabeled2017.json, the relevant script is as below:
from mmengine.fileio import load, dump
anns_train = load('instances_train2017.json')
anns_unlabeled = load('image_info_unlabeled2017.json')
anns_unlabeled['categories'] = anns_train['categories']
dump(anns_unlabeled, 'instances_unlabeled2017.json')
The processed dataset directory is as below:
mmdetection
├── data
│ ├── coco
│ │ ├── annotations
│ │ │ ├── image_info_unlabeled2017.json
│ │ │ ├── instances_train2017.json
│ │ │ ├── instances_unlabeled2017.json
│ │ │ ├── instances_val2017.json
│ │ ├── test2017
│ │ ├── train2017
│ │ ├── unlabeled2017
│ │ ├── val2017
Configure multi-branch pipeline¶
There are two main approaches to semi-supervised learning, consistency regularization and pseudo label. Consistency regularization often requires some careful design, while pseudo label have a simpler form and are easier to extend to downstream tasks. We adopt a teacher-student joint training semi-supervised object detection framework based on pseudo label, so labeled data and unlabeled data need to configure different data pipeline:
(1) Pipeline for labeled data:
# pipeline used to augment labeled data,
# which will be sent to student model for supervised training.
sup_pipeline = [
dict(type='LoadImageFromFile', backend_args=backend_args),
dict(type='LoadAnnotations', with_bbox=True),
dict(type='RandomResize', scale=scale, keep_ratio=True),
dict(type='RandomFlip', prob=0.5),
dict(type='RandAugment', aug_space=color_space, aug_num=1),
dict(type='FilterAnnotations', min_gt_bbox_wh=(1e-2, 1e-2)),
dict(type='MultiBranch', sup=dict(type='PackDetInputs'))
]
(2) Pipeline for unlabeled data:
# pipeline used to augment unlabeled data weakly,
# which will be sent to teacher model for predicting pseudo instances.
weak_pipeline = [
dict(type='RandomResize', scale=scale, keep_ratio=True),
dict(type='RandomFlip', prob=0.5),
dict(
type='PackDetInputs',
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
'scale_factor', 'flip', 'flip_direction',
'homography_matrix')),
]
# pipeline used to augment unlabeled data strongly,
# which will be sent to student model for unsupervised training.
strong_pipeline = [
dict(type='RandomResize', scale=scale, keep_ratio=True),
dict(type='RandomFlip', prob=0.5),
dict(
type='RandomOrder',
transforms=[
dict(type='RandAugment', aug_space=color_space, aug_num=1),
dict(type='RandAugment', aug_space=geometric, aug_num=1),
]),
dict(type='RandomErasing', n_patches=(1, 5), ratio=(0, 0.2)),
dict(type='FilterAnnotations', min_gt_bbox_wh=(1e-2, 1e-2)),
dict(
type='PackDetInputs',
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
'scale_factor', 'flip', 'flip_direction',
'homography_matrix')),
]
# pipeline used to augment unlabeled data into different views
unsup_pipeline = [
dict(type='LoadImageFromFile', backend_args=backend_args),
dict(type='LoadEmptyAnnotations'),
dict(
type='MultiBranch',
unsup_teacher=weak_pipeline,
unsup_student=strong_pipeline,
)
]
Configure semi-supervised dataloader¶
(1) Build a semi-supervised dataset. Use ConcatDataset to concatenate labeled and unlabeled datasets.
labeled_dataset = dict(
type=dataset_type,
data_root=data_root,
ann_file='annotations/instances_train2017.json',
data_prefix=dict(img='train2017/'),
filter_cfg=dict(filter_empty_gt=True, min_size=32),
pipeline=sup_pipeline)
unlabeled_dataset = dict(
type=dataset_type,
data_root=data_root,
ann_file='annotations/instances_unlabeled2017.json',
data_prefix=dict(img='unlabeled2017/'),
filter_cfg=dict(filter_empty_gt=False),
pipeline=unsup_pipeline)
train_dataloader = dict(
batch_size=batch_size,
num_workers=num_workers,
persistent_workers=True,
sampler=dict(
type='GroupMultiSourceSampler',
batch_size=batch_size,
source_ratio=[1, 4]),
dataset=dict(
type='ConcatDataset', datasets=[labeled_dataset, unlabeled_dataset]))
(2) Use multi-source dataset sampler. Use GroupMultiSourceSampler to sample data form batches from labeled_dataset and labeled_dataset, source_ratio controls the proportion of labeled data and unlabeled data in the batch. GroupMultiSourceSampler also ensures that the images in the same batch have similar aspect ratios. If you don’t need to guarantee the aspect ratio of the images in the batch, you can use MultiSourceSampler. The sampling diagram of GroupMultiSourceSampler is as below:
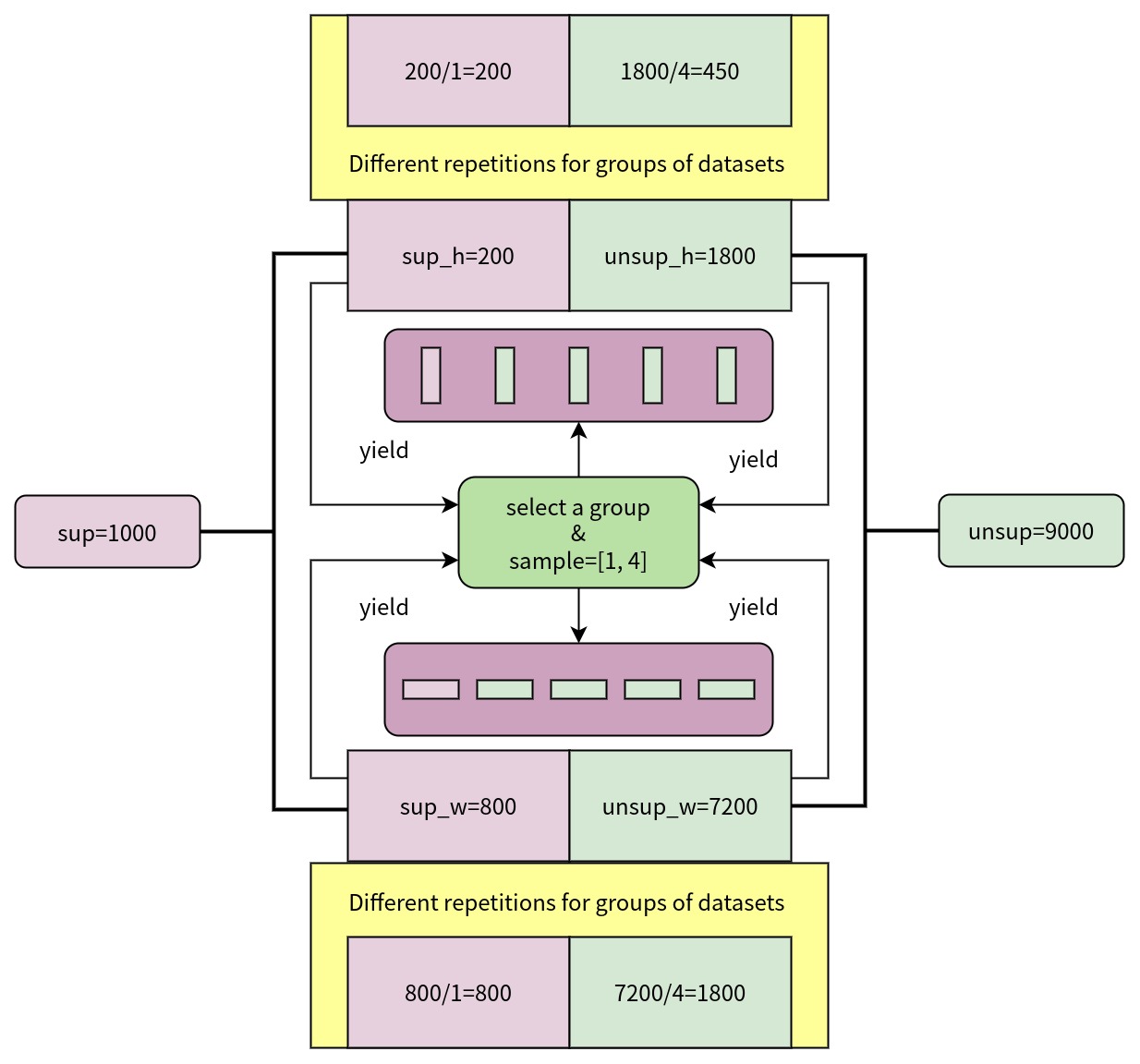
sup=1000 indicates that the scale of the labeled dataset is 1000, sup_h=200 indicates that the scale of the images with an aspect ratio greater than or equal to 1 in the labeled dataset is 200, and sup_w=800 indicates that the scale of the images with an aspect ratio less than 1 in the labeled dataset is 800,
unsup=9000 indicates that the scale of the unlabeled dataset is 9000, unsup_h=1800 indicates that the scale of the images with an aspect ratio greater than or equal to 1 in the unlabeled dataset is 1800, and unsup_w=7200 indicates the scale of the images with an aspect ratio less than 1 in the unlabeled dataset is 7200.
GroupMultiSourceSampler randomly selects a group according to the overall aspect ratio distribution of the images in the labeled dataset and the unlabeled dataset, and then sample data to form batches from the two datasets according to source_ratio, so labeled datasets and unlabeled datasets have different repetitions.
Configure semi-supervised model¶
We choose Faster R-CNN as detector for semi-supervised training. Take the semi-supervised object detection algorithm SoftTeacher as an example,
the model configuration can be inherited from _base_/models/faster-rcnn_r50_fpn.py, replacing the backbone network of the detector with caffe style.
Note that unlike the supervised training configs, Faster R-CNN as detector is an attribute of model, not model .
In addition, data_preprocessor needs to be set to MultiBranchDataPreprocessor, which is used to pad and normalize images from different pipelines.
Finally, parameters required for semi-supervised training and testing can be configured via semi_train_cfg and semi_test_cfg.
_base_ = [
'../_base_/models/faster-rcnn_r50_fpn.py', '../_base_/default_runtime.py',
'../_base_/datasets/semi_coco_detection.py'
]
detector = _base_.model
detector.data_preprocessor = dict(
type='DetDataPreprocessor',
mean=[103.530, 116.280, 123.675],
std=[1.0, 1.0, 1.0],
bgr_to_rgb=False,
pad_size_divisor=32)
detector.backbone = dict(
type='ResNet',
depth=50,
num_stages=4,
out_indices=(0, 1, 2, 3),
frozen_stages=1,
norm_cfg=dict(type='BN', requires_grad=False),
norm_eval=True,
style='caffe',
init_cfg=dict(
type='Pretrained',
checkpoint='open-mmlab://detectron2/resnet50_caffe'))
model = dict(
_delete_=True,
type='SoftTeacher',
detector=detector,
data_preprocessor=dict(
type='MultiBranchDataPreprocessor',
data_preprocessor=detector.data_preprocessor),
semi_train_cfg=dict(
freeze_teacher=True,
sup_weight=1.0,
unsup_weight=4.0,
pseudo_label_initial_score_thr=0.5,
rpn_pseudo_thr=0.9,
cls_pseudo_thr=0.9,
reg_pseudo_thr=0.02,
jitter_times=10,
jitter_scale=0.06,
min_pseudo_bbox_wh=(1e-2, 1e-2)),
semi_test_cfg=dict(predict_on='teacher'))
In addition, we also support semi-supervised training for other detection models, such as RetinaNet and Cascade R-CNN. Since SoftTeacher only supports Faster R-CNN, it needs to be replaced with SemiBaseDetector, example is as below:
_base_ = [
'../_base_/models/retinanet_r50_fpn.py', '../_base_/default_runtime.py',
'../_base_/datasets/semi_coco_detection.py'
]
detector = _base_.model
model = dict(
_delete_=True,
type='SemiBaseDetector',
detector=detector,
data_preprocessor=dict(
type='MultiBranchDataPreprocessor',
data_preprocessor=detector.data_preprocessor),
semi_train_cfg=dict(
freeze_teacher=True,
sup_weight=1.0,
unsup_weight=1.0,
cls_pseudo_thr=0.9,
min_pseudo_bbox_wh=(1e-2, 1e-2)),
semi_test_cfg=dict(predict_on='teacher'))
Following the semi-supervised training configuration of SoftTeacher, change batch_size to 2 and source_ratio to [1, 1], the experimental results of supervised and semi-supervised training of RetinaNet, Faster R-CNN, Cascade R-CNN and SoftTeacher on the 10% coco train2017 are as below:
| Model | Detector | BackBone | Style | sup-0.1-coco mAP | semi-0.1-coco mAP |
|---|---|---|---|---|---|
| SemiBaseDetector | RetinaNet | R-50-FPN | caffe | 23.5 | 27.7 |
| SemiBaseDetector | Faster R-CNN | R-50-FPN | caffe | 26.7 | 28.4 |
| SemiBaseDetector | Cascade R-CNN | R-50-FPN | caffe | 28.0 | 29.7 |
| SoftTeacher | Faster R-CNN | R-50-FPN | caffe | 26.7 | 31.1 |
Configure MeanTeacherHook¶
Usually, the teacher model is updated by Exponential Moving Average (EMA) the student model, and then the teacher model is optimized with the optimization of the student model, which can be achieved by configuring custom_hooks:
custom_hooks = [dict(type='MeanTeacherHook')]
Configure TeacherStudentValLoop¶
Since there are two models in the teacher-student joint training framework, we can replace ValLoop with TeacherStudentValLoop to test the accuracy of both models during the training process.
val_cfg = dict(type='TeacherStudentValLoop')