数据变换(待更新)¶
按照惯例,我们使用 Dataset 和 DataLoader 进行多进程的数据加载。Dataset 返回字典类型的数据,数据内容为模型 forward 方法的各个参数。由于在目标检测中,输入的图像数据具有不同的大小,我们在 MMCV 里引入一个新的 DataContainer 类去收集和分发不同大小的输入数据。更多细节请参考这里。
数据的准备流程和数据集是解耦的。通常一个数据集定义了如何处理标注数据(annotations)信息,而一个数据流程定义了准备一个数据字典的所有步骤。一个流程包括一系列的操作,每个操作都把一个字典作为输入,然后再输出一个新的字典给下一个变换操作。
我们在下图展示了一个经典的数据处理流程。蓝色块是数据处理操作,随着数据流程的处理,每个操作都可以在结果字典中加入新的键(标记为绿色)或更新现有的键(标记为橙色)。
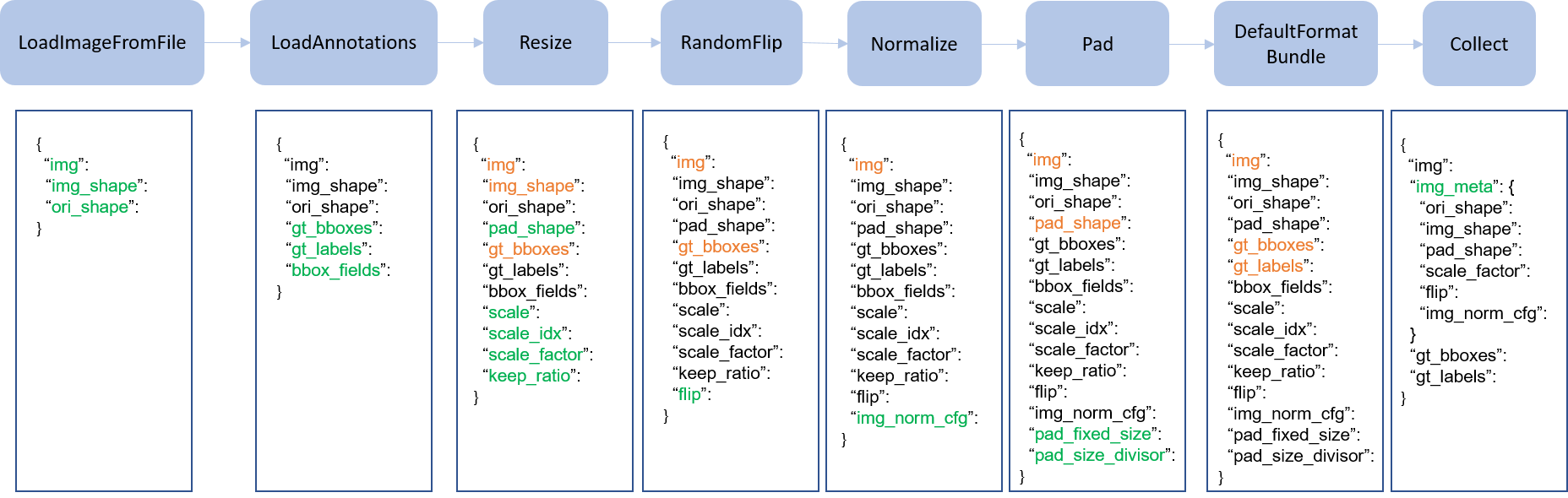
这些操作可以分为数据加载(data loading)、预处理(pre-processing)、格式变化(formatting)和测试时数据增强(test-time augmentation)。
下面的例子是 Faster R-CNN 的一个流程:
img_norm_cfg = dict(
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations', with_bbox=True),
dict(type='Resize', img_scale=(1333, 800), keep_ratio=True),
dict(type='RandomFlip', flip_ratio=0.5),
dict(type='Normalize', **img_norm_cfg),
dict(type='Pad', size_divisor=32),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels']),
]
test_pipeline = [
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(1333, 800),
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(type='Normalize', **img_norm_cfg),
dict(type='Pad', size_divisor=32),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img']),
])
]